Keywords
Research Methods and Statistics; Community Pediatrics; Epidemiology
Research Methods and Statistics; Community Pediatrics; Epidemiology
 How to cite: Keegan AA, Lambert B, Ingram J et al. Detecting and responding to fake responses to an online infant care survey in the UK [version 1; peer review: awaiting peer review]. NIHR Open Res 2026, 6:52 (https://doi.org/10.3310/nihropenres.14281.1)
First published: 29 May 2026, 6:52 (https://doi.org/10.3310/nihropenres.14281.1)
Latest published: 29 May 2026, 6:52 (https://doi.org/10.3310/nihropenres.14281.1)
How to cite: Keegan AA, Lambert B, Ingram J et al. Detecting and responding to fake responses to an online infant care survey in the UK [version 1; peer review: awaiting peer review]. NIHR Open Res 2026, 6:52 (https://doi.org/10.3310/nihropenres.14281.1)
First published: 29 May 2026, 6:52 (https://doi.org/10.3310/nihropenres.14281.1)
Latest published: 29 May 2026, 6:52 (https://doi.org/10.3310/nihropenres.14281.1)
Conducting online surveys can feel ‘too good to be true’; they are quick to create and disseminate. Using online surveys allows for rapid collection of large-scale data from geographically dispersed participants at low cost.1 The use of email and social media to reach respondents can make engaging in research more inclusive and help include underserved populations in research.2 Completing surveys online preserves anonymity supporting accurate data collection on sensitive topics.2, 3, 4, 3 However, ensuring anonymity makes it difficult to verify that responses are genuine.
The extent of survey fraud and its impact on findings are mostly unknown. Even small levels of fraud can distort results.4 Credé5 demonstrated that as little as 5% random response can significantly inflate observed correlations. Konstan6 excluded 11% of their responses as invalid; the fraudulent data falsely indicated a strong demand for Spanish-language HIV-prevention materials—findings not supported by the validated responses. Without proper validation, such distortions can lead to inappropriate recommendations. Online researchers are described as in an ‘arms race’ with online fraudsters; as new protections are introduced, they are quickly bypassed.7 Reports of fraudulent qualitative participants have also emerged.8 Despite these risks, survey fraud is seldom addressed in academic methods training, leaving many new researchers unaware of the issues when conducting online surveys.
Online surveys are particularly valuable in research involving families with young infants, many of whom seek reassurance in online communities.9 However, topics like infant care can be polarising, and families may fear judgement or social services involvement, especially if discussing potentially risky behaviours. This can lead to social desirability bias, or responding in ways perceived to be acceptable rather than truthful.10 Anonymity was expected to mitigate this in our study, encouraging honest disclosure. Additionally, the study was designed during the COVID-19 pandemic when face-to-face data collection was uncertain.
The Baby Sleep Project is a series of studies to support vulnerable families and prevent Sudden Unexpected Death in Infancy (SUDI).11 We launched a national survey on 14th June 2022 to understand infant care practices related to safer sleep. The study formed part of an NIHR Fellowship and was conducted via a respected academic online survey platform. The survey collected data on infant care practices relating to safer sleep advice given nationwide in England. As recommended by our public involvement group, an incentive for completing the survey was offered, where respondents could opt-in to be entered into a prize draw to win one of three £50 vouchers. The survey was intended to be conducted face-to-face but due to restrictions imposed by the COVID-19 pandemic at the time, the survey was distributed online.
The survey was promoted through printed postcards in children’s centres, health professionals in contact with families, and via two well-known children’s charities on Instagram, Facebook and X (formerly Twitter). Posts were public and shareable, allowing the survey link to be widely distributed.
To reduce the risk of survey fraud, participants were informed that prize winners would be contacted by email and asked to verify some data before receiving vouchers. Although multiple fake entries were possible, the risk was considered low due to the topic’s low controversy and lack of other incentives to interfere. The survey platform reported regular security testing, but lacked CAPTCHA protection, support for preventing multiple entries, or the ability to provide IP addresses.
The survey aimed to recruit parents or carers of babies under 1 year of age who lived in England. Survey completion was anonymous, however respondents could leave their email address or phone number at the end of the survey if they wanted to be contacted for an interview, receive the results of the survey or entered into the prize draw.
A group of 14 parent advisors (The Baby Sleep Project Family Advisors) met online to guide the study team on the project as a whole. They contributed to question design, recruitment approaches, and how to interpret the study findings. Members of the group also provided advice about spotting fake responses, and sense checked our ideas about inconsistencies in answers. Their recommendations shaped how we spotted implausible clothing combinations and discrepancies in co-sleeping answers. They also pointed out that completing a survey between midnight and 6 am should be an amber flag, not a red flag, as many parents are up in the night with infants and may have completed the survey genuinely at this time.
Once the survey closed, the researchers noticed unusual patterns in the data. Some answers didn’t make sense, some text responses were just random characters, and some entries came in within seconds of each other. This raised concerns that automated “bots” or individuals trying to win the prize might have submitted fake responses.
To deal with this, the team developed a five-step process:
1. Identify definitely genuine responses (such as people who later took part in an interview or verified their details when claiming a prize).
2. Find and remove duplicates, unless the respondent had twins.
3. Assess ‘red’ and ‘amber’ flags: Apply “red flags” for clear signs of fraud—like nonsense text, invalid emails, or contradictory answers. Apply “amber flags” for suspicious patterns—like unusual completion times, strange email formats, or inconsistent answers. Entries with two or more amber flags were treated as questionable.
4. Add back in validated responses if they had responded to an email to confirm they were genuine.
5. Analyse the included and excluded responses to see how much impact the fraud has had on the results.
In total, about 6% of responses were removed as likely fake. The team found that fake entries tended to give random or highly unusual answers that did not match real-world patterns.
Online survey fraud is increasingly common but rarely discussed. The article recommends that researchers build checks into their study design, use tools like CAPTCHA, and analyse data carefully to spot suspicious patterns.
We defined survey fraud using Lawlor and colleagues framework,4 including unique participant fraud, alias fraud and suspicious submissions. Unique fraud involves one individual submitting multiple responses, either intentionally (e.g., to claim incentives) or unintentionally (e.g., forgetting they had already participated). Alias fraud involves more sophisticated attempts to mask identity. Suspicious submissions refer to any entries potentially falling into either category.
Our identification process was iterative; checking all responses for expected and potentially deviating responses, reviewing the impact of each criteria on the overall dataset. The identification of genuine responses allowed us to test if we were omitting potentially genuine responses. It was important that we retained as much of the genuine data as possible, whilst still ensuring that suspicious submissions were identified.
We were guided by the Reflect, Expect, Analyse, Label (REAL) framework, developed by Lawlor and colleagues (2021) which asks: (1) Based on your recruitment and distribution practices, how might your survey be vulnerable?; (2) What are the patterns you would expect to see in survey data?; (3) How do expected patterns related to patterns in reality?; (4) What level of suspicion is sufficient to exclude data from your survey? Table 1 shows how we adapted this framework for our purposes.
Red flags were developed based on literature, expert advice, and technical support from the University of Bristol and the survey platform. Some flags, such as identical nonsense text entries, strongly indicate fraud, while others (e.g., long completion time) may have benign explanations. We also accounted for legitimate use of anonymous email addresses by some parents participating in paid surveys.
Our approach balanced the need to exclude clearly fraudulent responses (core red flags) while identifying combinations of amber flags that could indicate fraud, aiming to preserve genuine data wherever possible.
The survey closed after 5 months on November 11th, 2022, with 3,409 responses. During data cleaning, we identified potential fraud, initially flagged by repeated or irrelevant free text answers. We developed a five-stage process (Fig 1) to identify and remove fraudulent submissions using objective, replicable criteria, aiming for transparency and data integrity.
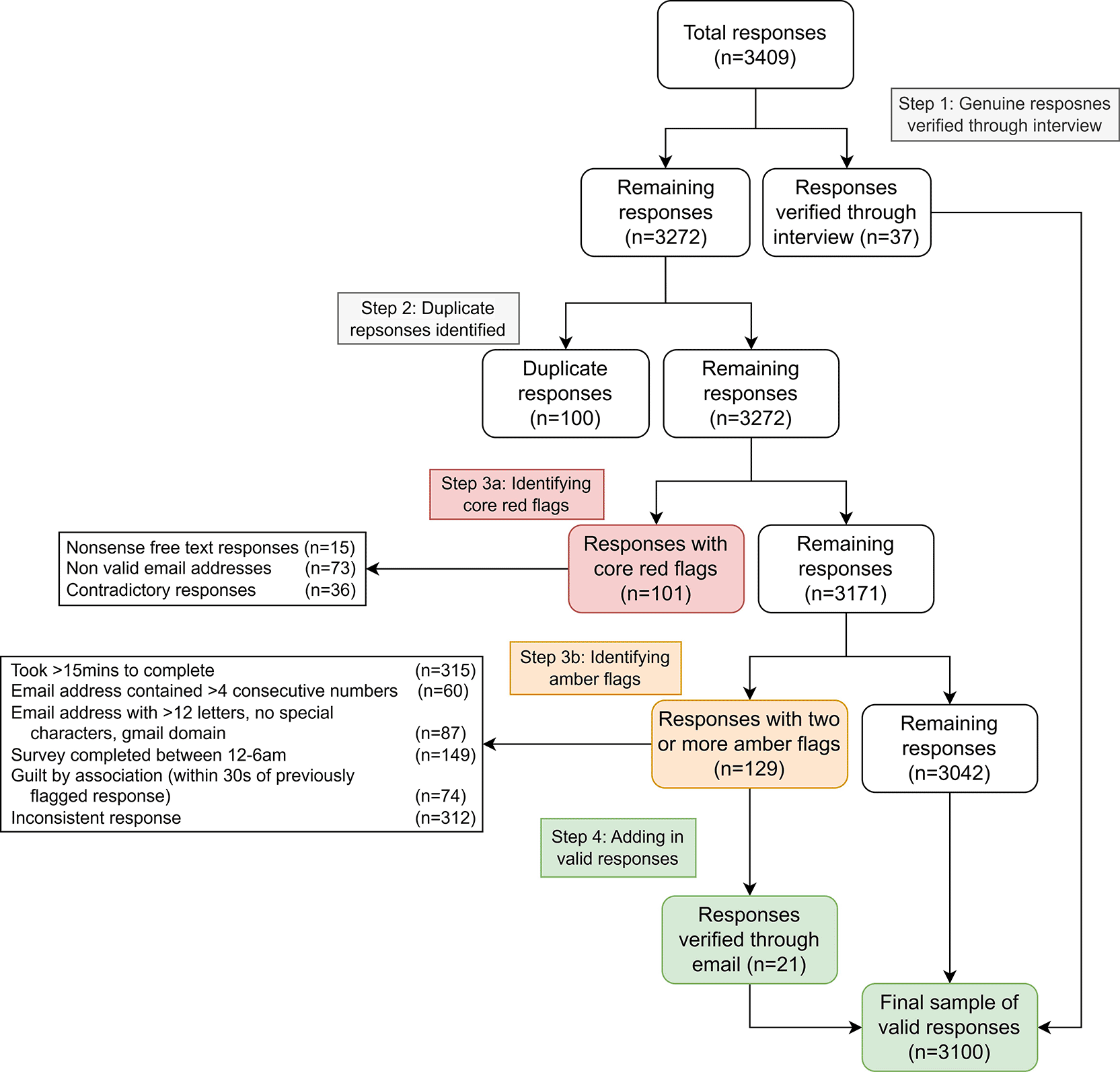
Some responses were verified as genuine and excluded from further checks:
1. Participated in a telephone interview (N = 34; one had twins)
2. Won a £50 prize (verified via email) N = 3
Total verified = 37; remaining unverified = 3,372.
89% (3049/3409) of responses included email addresses, which were used to identify duplicates. Duplicate responses from parents of twins were retained. For others, only the first response was kept. Most duplicates were not considered suspicious, with 100 non-twin duplicate responses removed.
We excluded all responses with any core red flags and those with 2 or more amber flags, based on their frequency and association with suspicious patterns.
Three core red flags identified 100 responses within our dataset as suspicious and were removed:
Individually, these flags were not enough for exclusion, but 2+ suggested higher suspicion. We derived them by analysing patterns in the 100 red-flagged responses. Table 2 demonstrates the number of responses highlighted as suspicious with the number of red and amber flags present.
1. Unusually long completion time (>15 mins). No responses were under 2 minutes. Descriptive statistics for completion times are shown in Table 3.
2. Emails with 5+ consecutive numbers (e.g., someone865798@gmail.com)
3. Suspicious email usernames (e.g., long strings of letters with no numbers/symbols from gmail.com)
4. Survey completed between midnight and 6 am
5. Completed within 20 seconds of a red-flagged submission
6 through 9. Inconsistencies in answers, including:
6. reasons for co-sleeping away from home
7. Implausible clothing combinations (e.g., baby sleeping in a hat only)
8. Discrepancies between “ever” and “last night” sleep surfaces
9. Reported co-sleeping not matched to selected sleep locations AND submitted within 20 seconds of another suspicious response
| Mean | SD | Quartiles | ||||
|---|---|---|---|---|---|---|
| minimum | 25% 1st quart | 50% 2nd quart | 75% 3rd quart | maximum | ||
| 10 mins | 24 mins | 2 mins | 5 mins | 7 mins | 9 mins | 1146 mins |
In total, we identified 230/3272 (7.0%) of the survey submissions as suspicious, 101 with any of the core red flags, 129 with two or more amber flags.
We contacted 223/230 participants flagged as suspicious but with valid emails, offering the chance to confirm eligibility. Of these, 21 (9%) were verified and reinstated. Seven could not be contacted (no email), leaving 209 permanently excluded and a final dataset of 3,100 responses for analysis.
We compared the ‘kept’ and ‘removed’ datasets to assess the impact of fraudulent submissions. Table 4 shows differences across three groups: responses included in the final analysis, those excluded for having two or more amber flags, and those excluded for any core red flag. As responses became more suspicious, answer distributions became more uniform—suggesting random selection.
For example, among responses excluded for core red flags, 50% reported neonatal unit admission, compared to 10–15% in population estimates and among included responses. Excluded responses also more often listed someone other than the mother as the respondent and reported multiple births, with 46.5% of core red flag responses selecting twin or triplet births. A similar pattern appeared for social work involvement: 61% of red-flagged responses reported this, compared to an expected national rate of ~3%. Differences also emerged in sleep environment questions, with excluded responses more frequently reporting non-supine infant sleep positions. Reports of changes to the infant’s usual sleep routine “last night” were also more common in excluded groups, again suggesting more random or inconsistent answers.
We have presented a description of the strategies used to identify and exclude suspicious submissions to an online survey. We applied the REAL framework to develop a strategy for identification of potentially fraudulent responses that could be objective, transparent and replicable (see Table 1). Overall, 209/3272 responses (6.4%) were identified as suspicious and removed from the dataset. Reported proportions of survey fraud in online surveys have ranged from 100%12 to 11%.6 Pozzar and colleagues12 recruited survey respondents to an Ovarian Cancer communication study through Social media (Facebook and Twitter) and labelled 94.5% of the responses as fraudulent and 5.5% of responses as suspicious. Quach and colleagues13 recruited parents for focus groups about adding the influenza vaccine to school-based immunisation programmes using social media, deal forum websites, online classified ads, mass media and email lists and determined that 36% of their responses were genuine after data cleaning, with 43% of the responses were flagged as multiple submissions with the other responses not meeting their screening criteria. Bowen and colleagues,14 in their survey of men who had sex with men (MSM), identified that 33% of their sample made multiple submissions.
The methods that we used to identify fraudulent responses in this paper reflected those used by other researchers; screening email addresses,6,7,14 screening free text responses,7 assessing time and speed of survey competition.3,6,7,14 Goodrich and colleagues (2023) used a high/low priority method of flagging suspicious submissions, similar to the red flag system outlined in this paper.15
As the level of survey fraud was unexpected, we revisited the reflect step before identifying fraudulent responses. We reviewed our dissemination methods and pinpointed vulnerabilities, noting spikes in suspicious submissions following shares by large organisations on social media. We took a cautious approach, prioritising a smaller, more reliable sample over a larger, riskier one. To recover genuine responses, we contacted excluded participants by email. While we couldn’t guarantee all replies were authentic, responses to verification emails allowed us to rule out alias fraud in those cases.
Suspicious submissions in this survey fell into two categories: unique participant fraud and alias fraud. About 3% of responses were legitimate or accidental duplicates, clearly identified by email address and removed in step 2. These were often submitted months apart, likely by individuals who forgot they had already responded.
Most suspicious entries were alias fraud, likely automated or bot-generated, as they were submitted within seconds of each other and took an unusually long time to complete. Notably, 10% of those flagged did not opt into the prize draw, suggesting the incentive was not always a motivation for fraudulent responses.
Survey fraud is rarely discussed in academic research, but deserves more attention. Online surveys already require cautious interpretation due to limited respondent information, and fraudulent responses can make analysis misleading. Those who conduct online surveys may find our processes helpful when considering interrogation of their own datasets.
1) Recognising the potential for fraud
Fraud should be considered before survey launch, with plans for identifying suspicious responses. Incorporating frameworks like REAL into protocols can help anticipate risks.4 Even non-incentivised surveys may be targeted by individuals aiming to disrupt for disruption’s sake, especially when shared publicly on social media. Alternative approaches, such as limiting open access or adding a verification step, may reduce risk.
2) Taking preventative measures
Survey platforms should support tools like CAPTCHA and ballot-box stuffing prevention (e.g., cookies to block repeat entries), though bots may bypass these.16 Additional techniques include invisible “honeypot” questions, mandatory free-text responses, and logic checks (e.g., comparing age and birthdate). When feasible, personalised single-use survey links and pre-screening can also reduce fraud.
3) Having a fraud analysis plan
Even with safeguards, fraudulent responses may still occur. A pre-specified fraud analysis plan should be in place before data analysis. This may involve obtaining ethical approval for IP access and including fraud checks in protocols from the outset.7 It is essential to have a procedure for reviewing suspicious entries and conducting sensitivity analyses to assess data validity.
Following on from our experiences with survey fraud, we have been able to push for further education and clarity for researchers planning to undertake research using online methods. We have been able to communicate the scope of the issue with our institution leading to the development of specific guidance on the prevention, identification and removal of fake responses to survey data and its inclusion in research training. The online survey platform agreed to provide more specific advice about survey distribution and the risk of automated or fraudulent responses in their help pages for users to consider prior to launching surveys.
The reality of online survey research is that survey fraud is inevitable,7 therefore it is vitally important that research standards are maintained and that strategies to ensure that research data are genuine are embedded into research protocols. The increasing use of online surveys and the ever-increasing threat of survey fraud has the potential to significantly impact research, resulting in real world consequences. We hope to uphold the integrity of our dataset by being transparent about our process of identifying potentially suspicious submissions and that through our openness we can guide and support other researchers who face the same predicament.
A favourable ethical opinion was given by the University of Bristol’s Faculty of Health Science Research Ethics Committee (FREC), Ref: 10331 on the 16th May 2022. All participants provided written informed consent prior to taking part in the study. The study was conducted in accordance with the University of Bristol’s Ethics of Research Policy and Procedure.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with NIHR Open Research
Already registered? Sign in
If you are a previous or current NIHR award holder, sign up for information about developments, publishing and publications from NIHR Open Research.
We'll keep you updated on any major new updates to NIHR Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)