Keywords
Open Science, Discrete-Event Simulation, Health Services Research, Web Applications, Python, Model Reuse, Reproducibility
Open Science, Discrete-Event Simulation, Health Services Research, Web Applications, Python, Model Reuse, Reproducibility
Since the previous version of the article we have done the following:
See the authors' detailed response to the review by Apostolos Kritikos
See the authors' detailed response to the review by Geraint Palmer
See the authors' detailed response to the review by Robert Smith
Health service delivery is complex and costly. Computer simulation can be used to provide decision-support for design or re-design of healthcare processes, accounting for the inherent uncertainty associated with service delivery. Models that represent key characteristics or behaviours of a system or process are developed. Experimenting with the model enables exploration of the potential impact of changes to the system without the costs and risk associated with real-world changes1,2. In healthcare, discrete-event simulation (DES) is the most common simulation method for modelling3. Reviews of the field demonstrate wide-ranging applications in health service delivery, for example evaluating operational performance, improving patient flow, and scheduling services4–6. Healthcare DES models are complex research artifacts: they are time-consuming to build, require clinical time and expertise, depend on specialist software and logic, and may be difficult to describe accurately using words and diagrams alone7.
DES for health service delivery modelling has traditionally been conducted using proprietary software such as Arena, Simul8 and Anylogic4,5,8. One reason is that proprietary simulation software is powerful, flexible, and user-friendly. For DES, proprietary licensed software have high costs per year, in the thousands, and restrictive licensing that limits how it can be used. This licensing causes two major issues for Open Science. The first is transparency of model artifacts9. If a researcher, or in some cases the NHS, is required to purchase or subscribe to the software, and does not have the means, then they cannot scrutinize how models really work: they cannot reuse the artifact for further research, and in extreme cases are prevented from using a model to support the redesign of NHS services. In some cases software vendors may provide a free-to-use “personal learning edition” of the simulation software. Here licensing allows researchers to inspect model code for their own learning, but legally prohibits use for further research or decision making. To avoid wasting the substantial clinical, and methodological expertise used in building models, new methods to improve the Open Science, transparency and usability of DES models are of critical importance.
Free and Open Source Software (FOSS) for simulation offers an alternative to proprietary software without the licensing restrictions that affect uptake, sharing, and reuse of model code10,11. In health service delivery research, computational analyses, and simulation studies can be conducted using FOSS tools built in the popular coding languages of Python, R, and Julia12–17. Use of a language such as Python has further benefits for research as models can now be integrated with the wider data science ecosystem for statistical modelling and machine learning. Contemporary approaches are available to publish the exact software and code artifacts used in a study. These provide credit to authors, and a way to cite outputs other than research articles, for example, open science archives (e.g. Zenodo, or the Open Science Framework), model specific archives (e.g. the Peer Models Network18 and CoMSeS Net19 and online computational environments such as Code Ocean.
One downside of code based FOSS models is that the switch from commercial software can be challenging. In recent years there has been an effort to reduce this entry barrier with new resources and textbooks aimed at the Operational Research community11,20,21. One open challenge is that these models are script-based and do not have have a user-friendly interface. In health service delivery research this may limit the uptake of new research tools for care pathway planning by NHS decision makers. This challenge is faced across all health data science disciplines, and methods are beginning to emerge to enable research to progress using FOSS. For example, in health economics and pharmacology, robust methods have been proposed to build user-friendly interfaces for models developed in R using Shiny, an open source framework for building web applications in R22,23. There are few examples of simulation studies for health services delivery that have developed free and open source DES models with a focus on use and reuse, using R or Python14,24,25. Several well-maintained DES libraries are available in Python, including simpy26, salabim27, and ciw28, while streamlit provides a relatively simple alternative to Shiny for building web apps in Python.
In this paper we focus on Open Science for health service delivery research and, in particular, Operational Research (OR) studies that use DES to model health care pathways and service delivery using Python. This study is aimed at researchers already familiar with developing healthcare DES models in Python. We detail approaches to enhance open science in healthcare DES by developing a method to organise Python DES models and provide a user friendly interface for model users using streamlit for shareable web apps.
This paper focuses on healthcare DES models developed using Python. It builds on pioneering work from health economics22, pharmacology23, and OR11,20 to support the community in adopting practices in R and Python FOSS tools to increase transparency and use/reuse of computational research artifacts. To complement existing work integrating Shiny in simulation models, we provide a method to add a streamlit interface to a Python model. We illustrate this with an application in DES using Python frameworks simpy26 and ciw28. We also detail a simple method for structuring Python DES models to enable reuse, extension, and swapping of simulation packages. Before presenting our method we provide an overview of FOSS, Python for computer simulation, and streamlit.
We developed a method for structuring DES models to enable reuse and linkage to a user-friendly streamlit web app. The method allows users of healthcare models to quickly create and execute one or more experiments with a DES simulation model deployed via a web app using Python. Our work is designed to improve dissemination and implementation of DES research in health services to support patient care.
FOSS and Python have gained significant popularity and use in the UK’s NHS in recent years. This transformation has been inspired via communities such as NHS-Python (and NHS-R) as well as NHS-England promoting the use of FOSS tools29. The Goldacre Review of research using health data30 has called for shared, reusable code for data analysis, that minimises inefficient duplication and enables research continuity. FOSS grants the rights for users to adapt and distribute copies however they choose. FOSS software within health data science is provided with an open license.
We chose Python as it is consistently ranked in the top 4 of Stack OverFlows’s most used programming languages (4th in 2022) and top 5 most loved programming languages by developers. Python is also synonymous with modern data science and is used extensively in research and development of computational methods and applications. We selected streamlit, over alternatives, for example, dash or shiny for Python, due to relatively shallow learning curves, and speed at which new users can build and deploy models. Given the code-based nature of our work we illustrate the implementation of streamlit in the form of a step-by-step tutorial.
We describe the steps involved in setting up a Python simulation model so that it is ready to incorporate into a web app, allowing user interactive simulation, basic tabular results presentation, basic interactive chart creation to display results, and use of our methods to create a large number of simulation experiments and run them in a single batch.
Our method is designed to be general to any DES package in Python. We primarily illustrate our method using a model built in simpy. We illustrate how our method supports interchangeability of models using a second simulation package called ciw and provide a full implementation in our Extended data31.
Although our case study model is simple, the methods we describe are applicable across more complex simulations. To illustrate, our online Extended data31 include an application to a second case study with time dependent arrivals, and multiple activities and classes of patient.
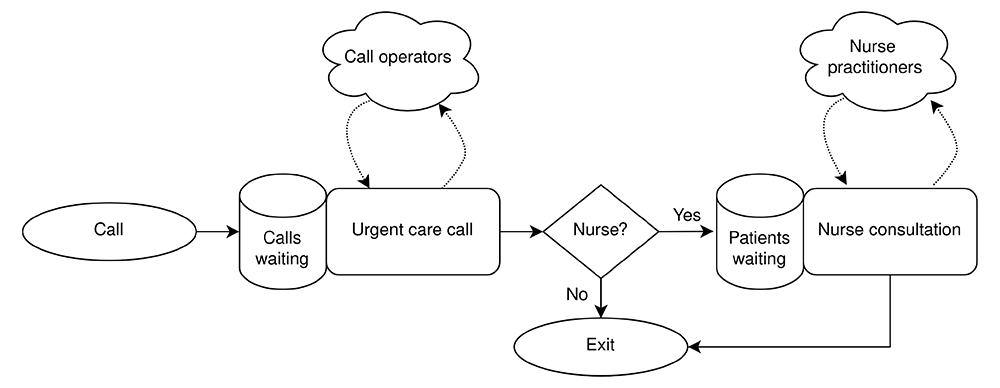
Our model is a stylised model of a typical urgent care call centre. Patient calls arrive at random to a call centre. Operators answer the calls, with a first in first out queue, triage the patient, interview following a standard script, and provide a call designation; for example, if the patient should travel to an emergency department, book an appointment in primary care with a General Practitioner (family doctor), or if a call back from a nurse is needed. If a caller needs to speak to a nurse they enter a first in first out queue until a nurse is available. Figure 1 illustrates patient flow in the model and use of resources.
Simpy is a DES package implemented in Python. It uses a process-based simulation worldview. DES models are built by defining Python generator functions and logic to request and return resources. Although simpy provides a full DES engine, the package does not contain many of the additional features offered by a full commercial simulation package, such as Arena or Simul8, including a user interface, instead simpy offers a lightweight, flexible tool that can be integrated with the rest of the Python data science ecosystem. It has been used to model a wide variety of health condition pathways and healthcare operations; for example, the coronavirus disease 2019 (COVID-19)32, renal12, stroke33,34, heart failure35, cancer care36, end of life care13, and operating theatre management24,37.
Streamlit is a software package to build web applications (apps) in Python. It has been designed to make web apps accessible to non-experts. A typical streamlit application is a short Python script.
Web apps built with streamlit can be interactive. Deployment of models to users could be as simple as a local Python script that provides a browser based front-end to a model, hosting the app in streamlit’s free to use community cloud, or as complex as deployment to paid infrastructure such as Google Cloud. Our method is applicable across all of these deployment methods. For simplicity we detail the building of a simple browser-based front-end to a simulation model that is run on a laptop or desktop.
All code was written in Python 3.9.16. The DES model was implemented in simpy 4.0.1 and ciw 2.3.7. We used streamlit 1.23.0 for web apps. Manipulation and analysis of simulation results was conducted using pandas 2.0.238 and numpy 1.25.039. Charts were created using matplotlib 3.7.140 and plotly 5.15.0.
The computational analyses were run on Intel i9-9900K CPU with 64GB RAM running Pop! OS 20.04 Linux.
In addition to the code presented in this paper we provide a more detailed online tutorial in a Jupyter book (https://health-data-science-or.github.io/simpy-streamlit-tutorial/). The code and book are archived using Zenodo31. Users can also obtain code from out GitHub repository: https://github.com/health-data-science-OR/simpy-streamlit-tutorial.
As others have stated, a web application should allow a user to change parameter values and rerun the model22. We add to this definition: a web app should provide a way for users to run more than one experiment at a time. By experiment we mean a change in one or more input parameters of the model. This type of experimentation is sometimes termed ‘what-if’ analysis and is highly relevant to operational research in healthcare2. Figure 2 illustrates the main concepts in the setup of our approach. We briefly outline these before describing implementation and code in our case study.
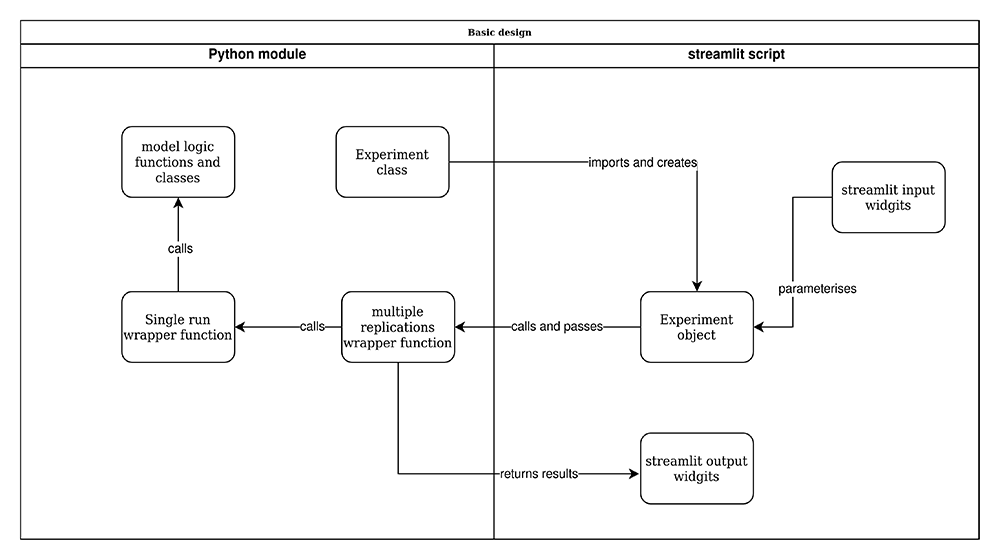
Encapsulating model logic in a Python module. Our method structures code and models so that a web app front-end does not depend on the simulation software package, or detailed logic of the model code. The opposite is also true, the implementation of the model is not affected by the logic or decisions made in the web app. Our approach ensures that a model is designed so that it can be run from a standard Python script, Jupyter notebook, or even a command line programme.
When combined with the model wrapper functions we propose in the next two sections, the simulation model becomes “swap-able”. In the language of software development, this would be called modular code. This allows researchers to easily explore different implementations of a model in different software. For example, a model may have been developed in simpy, but is re-implemented in salabim or ciw without any change to the web app itself. To a lesser degree, this also simplifies the implementation of experiments that vary the process logic within a simulation as well as quantitative parameters; for example, modelling an emergency department with and without rapid assessment and treatment protocols as patients arrive. A caveat in this second case is that depending on the process logic chosen, the web app might require additional logic to vary the parameters that are available to users.
We propose two ways to encapsulate a full model in Python. The first is to create a standard Python module (e.g. called model.py) that contains the simulation model and associated functions. I.e. model logic, functions, classes, and constants (for example, functions to generate patient arrivals to a health care service). Second, a Python package could be created and possibly deployed via the Python Package Index. Once installed the package acts very much like a module with a user importing functionality to run model experiments. Of these two methods the simplest to maintain in a modelling study is a Python module.
Experiment class. In our approach, code that uses the simulation model does not directly import model logic. Instead it relies on an Experiment class and a wrapper function.
The Experiment class is tightly coupled to the design of the simulation model. It contains a configuration of the simulation model that can be executed to obtain results. Another way to describe an experiment is that it is a collection of input parameters for the simulation model. For example, in a study of a cancer pathway a user might set up two experiments: one containing the default number of screening slots on a given day and one containing an increment. The results of the experiments (such as patient waiting time and resource utilisation) can then be compared.
Wrapping up a run of the model with single run(). This function acts as a wrapper to run a simulated experiment and process end of run results. A key aspect of the design is that single_run() accepts an instance of Experiment. The code then sets up the model following the user-set parameters, executes a single run of the model and returns results. Listing 1 provides pseudo code for the design of this function. It is indicative of the general pattern you will follow; the exact details will vary depending on the simulation package in use.
1 SUBROUTINE single_run(experiment, run_length): 2 setup_results_collection(experiment) 3 model = create_simulation_model(experiment) 4 results = run_model(model, run_length) 5 summary_results = process_results(results) 6 RETURN summary_results 7 END SUBROUTINE
multiple replications() wrapper function. The most likely usage scenario is that a model is run using multiple independent replications. This is a simple function that accepts an Experiment object and the number of replications to run. It then calls the single_run() function the appropriate number of times to create the distribution of results.
The streamlit script. The script contains all of the logic for the web app; for example, user settings, results tables and information about the simulation model.
The script imports the Experiment class, and the multiple_replications() wrapper function from the simulation model module. This is all that is needed to enable the interaction between the front-end and the model.
streamlit input widgets. The software has a number of standard input widgets available. For example, sliders, and text boxes to allow users to vary numeric values representing model parameters, and buttons to allow users to run models.
Experiment object. The script creates one or more instances of Experiment. The experiment object is parameterised by the script. For example, in an urgent care call centre two key parameters might be the number of call operators who handle incoming patient calls and nurses on duty and available for urgent call backs. The streamlit script might vary these inputs using the two values contained in streamlit input sliders.
Calling multiple replications(). The interface is set up so that a user clicks on a streamlit button and passes a parameterised instance of Experiment to multiple_replications() along with the number of replications to run.
streamlit output widgets. The multiple_replications() returns some form of results to the streamlit script; for example, a pandas.Dataframe containing results of each replication. The streamlit script then uses a output widget e.g. a streamlit.dataframe to display the results to the user.
The code examples in this study have been created using a conda virtual environment. An analogy for a virtual environment is a box within an operating system. Inside the box, a specific version of Python is installed along with specific versions of data science and simulation libraries such as simpy. There can be multiple virtual environments within one machine. The approach attempts to minimise software dependency conflicts between projects. Full details of how to install our environment, along with a supporting video, is available in our Extended data31. We note if users are familiar with other virtual environment tools such as poetry then this can also be used.
To recreate the model from scratch, see our Extended data31 for step by step instructions. Here we provide an overview of the main functions used to implement model logic.
The function arrivals_generator() is a simpy process for creating patient arrivals to the urgent care call centre. It contains a loop that continually samples the time until the next arrival using the Exponential distribution. Each patient arrival is allocated a new service process.
The function service() defines all of the logic after a caller has arrived. This includes requesting and queuing for a call operator resource, sampling call duration from a Triangular distribution, sampling if a nurse call back is required from a Bernoulli distribution, requesting and queuing for a nurse resource, and finally sampling nurse call duration from Uniform distribution. The function service() also collects patient waiting time and resource utilisation as the simulation executes.
The Experiment class encapsulates a set of input parameters that configure the simulation model. The overall design of a class representing an experiment will depend on the simulation study, and to some extent user preference. Here we advocate one key design principal:
Make use of default values for input parameters, either from constant variables, or read in from file.
Lines 6–20 of Listing 2 illustrate the use of default parameters when creating an instance of Experiment; for example, N_NURSES provides a default number of nurses. In the implementation these are variables with module level scope. They are combined with Python’s optional arguments for methods. This approach means that it is simple to create experiments with default or new parameter values. Listing 3 illustrates the method across three experiments: an experiment using all defaults; an experiment that varies the number of call operators; and an experiment that varies the number of call operators and nurses.
1 class Experiment: 2 """ 3 Parameter class for simulation model 4 """ 5 6 def __init__( 7 self, 8 n_operators=N_OPERATORS, 9 n_nurses=N_NURSES, 10 mean_iat=MEAN_IAT, 11 call_low=CALL_LOW, 12 call_mode=CALL_MODE, 13 call_high=CALL_HIGH, 14 chance_callback=CHANCE_CALLBACK, 15 nurse_call_low=NURSE_CALL_LOW, 16 nurse_call_high=NURSE_CALL_HIGH, 17 arrival_seed=None, 18 call_seed=None, 19 callback_seed=None, 20 nurse_seed=None, 21 ): 22 """ 23 The init method sets up our defaults, resource 24 counts, dists, + result collection objects. 25 """ 26 # no. resources 27 self.n_operators = n_operators 28 self.n_nurses = n_nurses 29 30 # create distribution objects 31 self.arrival_dist = Exponential(mean_iat, 32 arrival_seed) 33 self.call_dist = Triangular(call_low, call_mode, 34 call_high, call_seed) 35 36 self.callback_dist = Bernoulli(chance_callback, 37 callback_seed) 38 39 self.nurse_dist = Uniform(nurse_call_low, 40 nurse_call_high, 41 nurse_seed) 42 43 # resources 44 # these variable are placeholders. 45 self.operators = None 46 self.nurses = None 47 48 # initialise results to zero 49 self.init_results_variables() 50 51 def init_results_variables(self): 52 """ 53 Initialise all of the experiment variables used 54 in results collection. This method is called at 55 the start of each replication. 56 """ 57 # variable used to store results of experiment 58 self.results = {} 59 self.results["waiting_times"] = [] 60 61 # total operator usage time 62 self.results["total_call_duration"] = 0.0 63 64 # nurse sub process results collection 65 self.results["nurse_waiting_times"] = [] 66 self.results["total_nurse_call_duration"] = 0.0
1 default_experiment = Experiment() 2 extra_operator = Experiment(n_operators=14) 3 extra_operator_and_nurse = Experiment(n_operators=14, n_nurses=10)
The function single_run() is detailed in Listing 4. The function accepts an instance of Experiment and optionally a user specified simulation run length. Logically the function is a very simple wrapper for a single replication of the the model configured using the input parameters in the model. It returns a summary of the results from that replication (e.g. the mean operator waiting time in the replication).
In our simpy example, lines 27 – 38 creates a simulation environment, operator and nurse resources, sets up arrivals_generator() as a simpy process, and executes the model. Lines 41–60 are executed when the simulation is complete and calculate summary variables. Note these might preferably be refactored into an end_of_run_results() function for instances with a large number of model metrics.
1 def single_run(experiment, 2 rc_period=RESULTS_COLLECTION_PERIOD): 3 """ 4 Perform a single run of the model and return 5 a dictionary of results 6 7 Parameters: 8 ----------- 9 experiment: Experiment 10 The experiment/paramaters to use with model 11 12 rc_period: float, optional 13 (default=RESULTS_COLLECTION_PERIOD) 14 Results collection period for simulation. 15 16 Returns: 17 -------- 18 dict 19 """ 20 # results dictionary. Each KPI is a new entry. 21 run_results = {} 22 23 # reset all results variables to zero and empty 24 experiment.init_results_variables() 25 26 # environment is (re) created inside single run 27 env = simpy.Environment() 28 29 # create the resources 30 experiment.operators = simpy.Resource(env, 31 experiment.n_operators) 32 33 experiment.nurses = simpy.Resource(env, 34 experiment.n_nurses) 35 36 # setup arrivals_generators as simpy process 37 env.process(arrivals_generator(env, experiment)) 38 env.run(until=rc_period) 39 40 # end of run results: calculate mean waiting time 41 run_results["01_mean_waiting_time"] = np.mean( 42 experiment.results["waiting_times"] 43 ) 44 45 # end of run results: calculate mean operator utilisation 46 run_results["02_operator_util"] = ( 47 experiment.results["total_call_duration"] 48 / (rc_period * experiment.n_operators) 49 ) * 100.0 50 51 # end of run results: nurse waiting time 52 run_results["03 _mean_nurse_waiting_time"] = np.mean( 53 experiment.results["nurse_waiting_times"] 54 ) 55 56 # end of run results: calculate mean nurse utilisation 57 run_results["04 _nurse_util"] = ( 58 experiment.results["total_nurse_call_duration"] 59 / (rc_period * experiment.n_nurses) 60 ) * 100.0 61 62 # return the results from the run of the model 63 return run_results
The multiple_replications() function is simpler than single_run(). It is detailed in Listing 5. In line 26 a Python list comprehension is used to repeatedly loop and execute single_run() and create a Python list. Each item in the list is a dict containing the results of a single replication of the model. Lines 30 to 32 then format the results as pandas.Dataframe.
1 def multiple_replications( 2 experiment, rc_period=RESULTS_COLLECTION_PERIOD, 3 n_reps=5): 4 """ 5 Perform multiple replications of the model. 6 7 Params: 8 ------ 9 experiment: Experiment 10 The experiment/paramaters to use with model 11 12 rc_period: float, optional 13 (default = DEFAULT_RESULTS_COLLECTION_PERIOD) 14 results collection period. 15 the number of minutes to run the model to collect results 16 17 n_reps: int, optional (default=5) 18 Number of independent replications to run. 19 20 Returns: 21 -------- 22 pandas.DataFrame 23 """ 24 25 # loop over single run to generate lisy of results dicts. 26 results = [single_run(experiment, rc_period) 27 for rep in range(n_reps)] 28 29 # format and return results in a dataframe 30 df_results = pd.DataFrame(results) 31 df_results.index = np.arange(1, len(df_results) + 1) 32 df_results.index.name = "rep" 33 return df_results
Before moving on to building a web app it is recommended that a basic Python script is created to test the code. Listing 6 assumes that the model code and wrapper functions have been stored in a Python module called model.py. Line 1 illustrates that all that a model user needs do is import Experiment and multiple_replications(). In our example, the user is only interested in varying the number of operators, nurses, and the chance of a callback. Lines 14–20 then parameterise the experiment and execute the model.
In a real simulation project it is recommended that more extensive code testing and verification of model logic is conducted. The full breadth of testing strategies available is out of scope for this tutorial. Interested readers are directed to the code testing section of The Turing Way41 and to an introduction to Test Driven Development and Unit Testing in the context of computer simulation42.
1 from model import Experiment, multiple_replications 2 3 # set number of resources 4 n_operators = 13 5 n_nurses = 9 6 7 # set chance of nurse 8 chance_callback = 0.4 9 10 # set number of replications 11 n_reps = 5 12 13 # create experiment 14 exp = Experiment( 15 n_operators=n_operators, n_nurses=n_nurses, 16 chance_callback=chance_callback 17 ) 18 19 # run multiple replications of experment 20 results = multiple_replications(exp, n_reps=n_reps) 21 22 # show results 23 print(results.describe())
An example web app, for the urgent care call centre, is illustrated in Figure 3. An interactive version of the app is also available via Streamlit’s community cloud https://simpy-app-tutorial.streamlit.app.
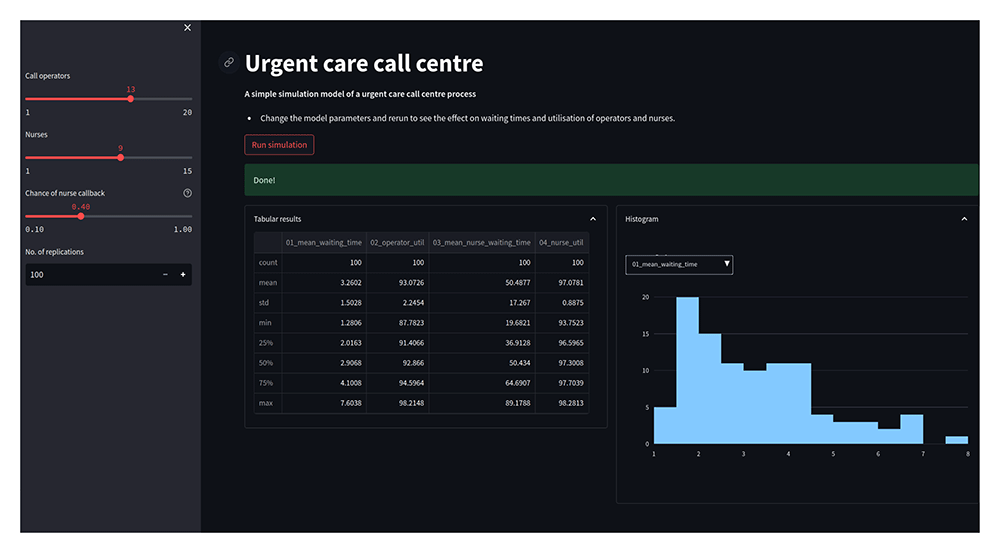
Shown is a screen shot of app running in a browser window. The app includes sliders for varying input parameters, and a interactive histogram to display results.
In summary the web app provides the following functionality:
1. Sliders will allow a user to vary the number of operators, nurses, and the probability of a nurse callback;
2. For a given configuration, run an experiment of the model when a button is clicked;
3. The model will provide feedback to the user to let them know an experiment is running and when it has completed.
4. Display the summary statistics of the results of an experiment in a table and interactive histogram.
We also provide a title and some explanatory text for the model. For readers who wish to reproduce the web app, we recommend that Listing 6 is used as a starting point. Users can then incrementally makes changes to the script as we outline below. The script should be renamed basic_app.py.
At the top of the script add import streamlit as st. This will mean the script can now be launched as a streamlit app. We will also include a title for the app using st.title(‘Urgent care call centre’). The app can now be launched from the command prompt (terminal on Linux and Mac): streamlit run basic_app.py
At the moment the model runs once - when the app starts. We will now add a st.button widget control when the app runs. In streamlit this is implemented using a Python if statement that checks the boolean value of the button. The use of a conditional may appear unintuitive at first, and is related to the way streamlit executes a script. We explain this in more detail in the next step.
After the model has executed the experiment, we need a way to display results to a user. We know that multiple_replications() returns a tabular result in the form of a dataframe. So we opt to use st.dataframe to display a formatted table to the user. This will appear underneath the button.
Listing 7 details the code from steps 1 and 2. The execution of the model is implemented in lines 31 to 36.
1 # ################################################################# 2 # MODIFICATION: import streamlit 3 import streamlit as st 4 5 # ################################################################## 6 from model import Experiment, multiple_replications 7 8 # ################################################################# 9 # MODIFICATION: We add in a title for our web app’s page 10 st.title("Urgent care call centre") 11 ################################################################### 12 13 # set number of resources 14 n_operators = 13 15 n_nurses = 9 16 17 # set chance of nurse 18 chance_callback = 0.4 19 20 # set number of replications 21 n_reps = 5 22 23 # create experiment 24 exp = Experiment( 25 n_operators=n_operators, n_nurses=n_nurses, 26 chance_callback=chance_callback 27 ) 28 29 ################################################################### 30 # MODIFICATION: press a streamlit button to run the model 31 if st.button("Run simulation"): 32 # run multiple replications of experment 33 results = multiple_replications(exp, n_reps=n_reps) 34 35 # show results 36 st.dataframe(results.describe()) 37 ###################################################################
We will now modify our app so that it is interactive; i.e., a user will be able to vary the parameters on screen to run custom experiments. We will do this using streamlit.slider and st.number_input widgets. Both of these functions display a streamlit input widget and returns a numeric value that can be assigned to a variable. Listing 8 illustrates the creation of a slider and number input. The variables n_nurses and n_reps are the same data type as seen in Listing 7. The functions take several mandatory and optional parameters. For example with a slider we have provided the text to display to a user, the minimum and maximum values, the default value and the step size between one value and the next.
1 n_nurses = st.slider(’Nurses’, 1, 15, 9, step=1) 2 n_reps = st.number_input("No. of replications", 100, 1_000, step=1)
It is now essential to understand how streamlit executes a script. Each time a user updates the value of a slider or clicks the run button streamlit executes the full Python script file i.e. from top to bottom. This means, for example, that the integer value of n_nurses changes each time the slider is moved. We can now also make sense of the use of an if statement with the st.button function. When the button is clicked it is assigned the value True. streamlit then executes the full script and will also execute the conditional logic contained under the if statement. When a slider is changed the button has a value of False so the model will not run unnecessarily. Listing 9 details the code within the modified script.
1 import streamlit as st 2 from model import Experiment, multiple_replications 3 4 # We add in a title for our web app’s page 5 st.title("Urgent care call centre") 6 7 # ################################################################# 8 # MODIFICATION: user experiment via app 9 10 # set number of resources 11 n_operators = st.slider("Call operators", 1, 20, 13, step=1) 12 n_nurses = st.slider("Nurses", 1, 15, 9, step=1) 13 14 # set chance of nurse 15 chance_callback = st.slider( 16 "Chance of nurse callback", 0.1, 1.0, 0.4, step=0.05) 17 18 # set number of replications 19 n_reps = st.number_input("No. of replications", 100, 1_000, step=1) 20 21 # ################################################################## 22 23 # create experiment 24 exp = Experiment( 25 n_operators=n_operators, n_nurses=n_nurses, 26 chance_callback=chance_callback 27 ) 28 29 # A user must press a streamlit button to run the model 30 if st.button("Run simulation"): 31 # run multiple replications of experment 32 results=multiple_replications(exp, n_reps=n_reps) 33 34 # show results 35 st.dataframe(results.describe())
To help usability, streamlit provides a number of simple features. We will implement three of these: a side bar that holds all of the input widgets, feedback to user that the model is running in the background, and a success box to report that the model run has completed.
A side bar is a section of the app that can be hidden or expanded depending on user preference, added using a Python with statement and st.sidebar. Its implementation can be seen in Listing 10 lines 10 to 21. Note that the widget code has been indented to ensure that it falls within the with statement block.
The second modification uses another with statement, this time combined with st.spinner. The spinner provides a simple animated prompt to users while the simulation is running. The code falls underneath the button logic for running the simulation model and can be seen in line 32 in Listing 10. Note again the indentation of the logic that will execute while the spinner is displayed on line 35. After the experiment is completed an st.success function is used to display a message of ‘Done’ to the user.
1 import streamlit as st 2 from model import Experiment, multiple_replications 3 4 # We add in a title for our web app’s page 5 st.title("Urgent care call centre") 6 7 # ################################################################# 8 # MODIFICATION: side bar 9 10 with st.sidebar: 11 # set number of resources 12 n_operators = st.slider("Call operators", 1, 20, 13, step=1) 13 n_nurses = st.slider("Nurses", 1, 15, 9, step=1) 14 15 # set chance of nurse 16 chance_callback = st.slider( 17 "Chance of nurse callback", 0.1, 1.0, 0.4, step=0.05 18 ) 19 20 # set number of replications 21 n_reps = st.slider("No. of replications", 5, 100, step=1) 22 23 # ################################################################# 24 25 # create experiment 26 exp = Experiment( 27 n_operators=n_operators, n_nurses=n_nurses, 28 chance_callback=chance_callback 29 ) 30 31 # A user must press a streamlit button to run the model 32 if st.button("Run simulation"): 33 # ############################################################# 34 # MODIFICATION: add a spinner and then display success box 35 with st.spinner("Simulating the urgent care system..."): 36 # run multiple replications of experment 37 results = multiple_replications(exp, n_reps=n_reps) 38 39 st.success("Done !") 40 # ############################################################# 41 42 # show results 43 st.dataframe(results.describe())
There are many options for visualisation in Python: e.g. matplotlib, plotly, altair, or bokeh. These are not specific to streamlit, and a full introduction to these packages is out of scope. Here we provide a simple example chart using plotly: a free and open source library for interactive charting. A matplotlib chart would be a fine choice as an alternative; however, we opt for an interactive chart to maximise the benefits offered from a web app. Our supplementary material details the coding of a function called create_user_filtered_hist. The chart is illustrated on the right hand side of Figure 3. The function accepts the results dataframe returns from the experiment. The histogram chart displays the distribution of a single performance measure across replications. The user is able to select a performance measure displayed from the full list using a drop down list. Note this is all achieved through plotly and avoids any complexity issues with the persistence of simulation results in the web app.
Listing 11 provides an extract of a streamlit script that makes use of the plotly function (see Extended data for the full listing). In the script we provide two further approaches to clean up the user interface and improve usability. We create two columns for side by side result display using st.columns(2) (line 8). We place the results table and plotly chart in these columns.
1 if st.button("Run simulation"): 2 3 with st.spinner(’Simulating the urgent care system... ’): 4 results = multiple_replications(exp, n_reps=n_reps) 5 st.success(’Done !’) 6 7 # create column layout 8 col1, col2 = st.columns(2) 9 with col1.expander(’Tabular results’, expanded=True): 10 # show tabular results 11 st.dataframe(results. describe()) 12 13 with col2.expander(’Histogram’, expanded=True): 14 # create histogram and call plotly function 15 fig = create_user_filtered_hist(results) 16 st.plotly_chart(fig, use_container_width=True)
The Experiment class provides a simple way to run multiple experiments in a batch. To do so we can create multiple instances of Experiment, each with a different set of inputs for the model. These are then executed in a loop.
A method to implement this in streamlit is to upload a Comma Separated Value (.CSV) file containing a list of experiments to the web app. This can be stored internally as a pandas.Dataframe and displayed using a streamlit widget such as st.table. A user can then edit experiment files locally on their own machine (for example, using a spreadsheet software, or using CSV viewer/editor extensions for Jupyter-Lab or Visual Studio Code) and upload, inspect, and run, and view results in the app. Example code to implement the approach is included in the Extended data31. Figure 4 illustrates the web app it creates.
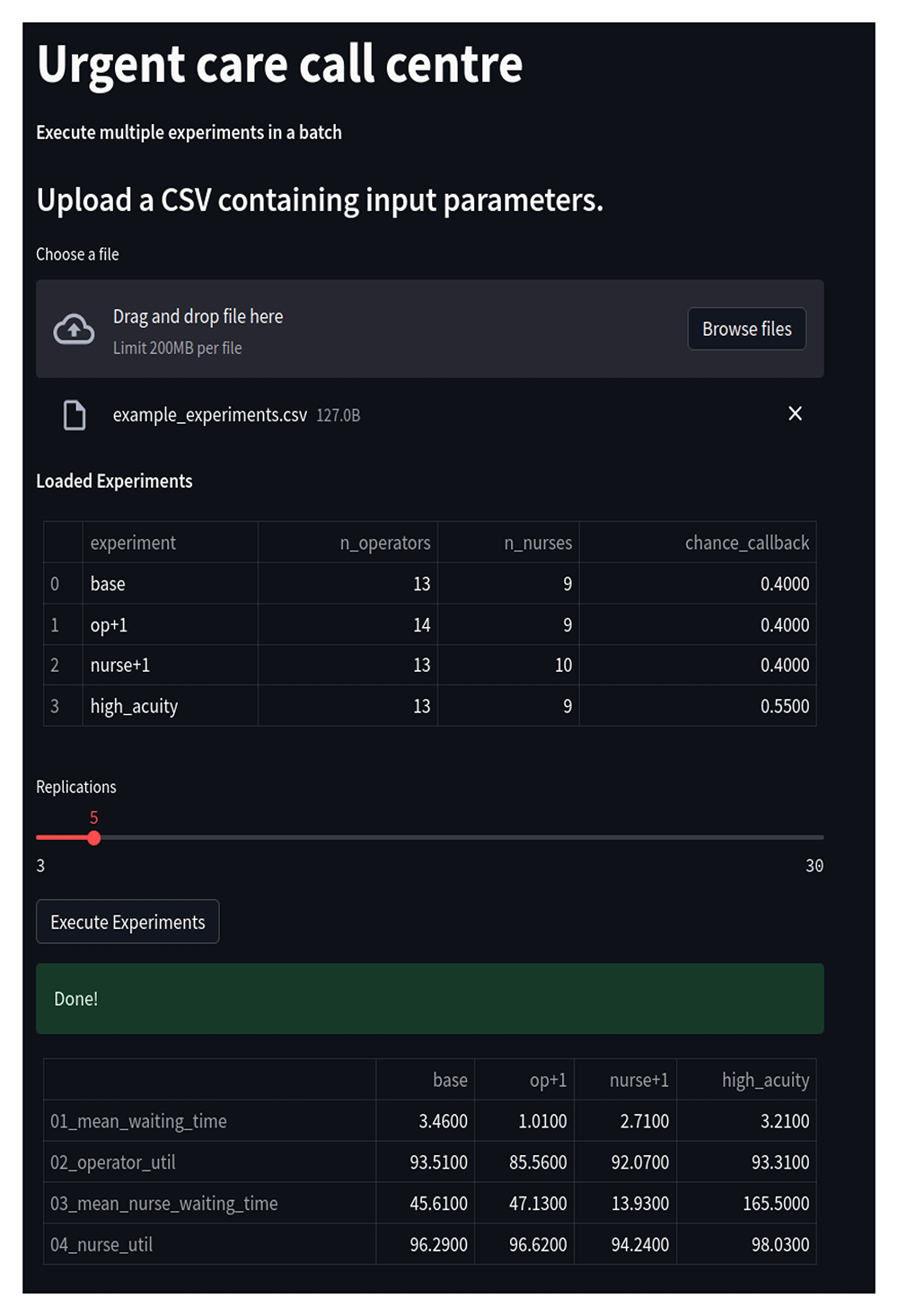
Shown is a screen shot of the app running in a browser window. The app has loaded and executed a CSV file containing four experiments. A table summarises experiment results.
Our DES model has been implemented in simpy, but our approach allows for this to be replaced if required. A high-quality alternative to simpy is ciw28: a FOSS package for discrete-event simulation of queuing networks. A full overview of ciw is out of scope; we refer interested readers to its extensive online documentation.
To make the change we only need to update model.py. The streamlit script does not need to be modified. The main modifications are to the single_run() function -that now creates an instance of a ciw network model and runs it for one replication - and Experiment that now uses ciw’s built in distributions. See the the online Extended data31 for full code listings. The ciw implementation provides qualitatively identical results and the same conclusions as simpy.
We demonstrate how to build a user-friendly interface to DES models coded in Python using streamlit. Our work aims to enhance Open Science within health service delivery and OR. Our approach supports researchers to share their computer models with other research teams and the NHS. Our Python method work is complementary to existing studies in Health Economic Evaluation and Markov modelling. Although no DES examples are available, modellers aiming to use an R DES package such as Simmer may wish to consult these sources for support22,23.
Strengths of our approach include a simple way to structure DES model Python code to allow for reuse, extension, and replacement, of models without the need to heavily modify a user interface. We demonstrated the latter by switching from simpy to ciw, although the approach would work just as well with different DES packages (e.g. salabim). Our method focus is DES, but the wrapper functions and experiment structure may generalise to other methods that use simulation. A closely related candidate method is Agent Based Simulation within healthcare as it makes use of stochastic sampling, multiple replications and experiments.
The apps created in the previous sections can be shared with other researchers and the NHS using a very simple method: code and virtual environment files are committed to GitHub (or alternative such as GitLab). These can then be downloaded and run on a laptop or desktop. Python has an advantage that it is a cross-platform language, i.e. code will run on Microsoft Windows, Mac OS or Linux10. Alternatively users can make use of streamlit community cloud, containerisation (e.g using Docker); or creating an .exe file (on Microsoft Windows). There is also the more complex option to host the web app remotely and pay for more powerful computing infrastructure (e.g. Google Cloud).
Another strength of our approach is that our multiple_replications function is easily parallelisable using Python’s joblib library. If the model is used locally, there may be a large time saving benefit of taking this approach, i.e. running parallel replications on a laptop with 20 virtual cores. However, in general these benefits are unlikely to transfer to web based models10 without using a paid tier offered by a web app hosting provider. For example, Streamlit’s community cloud or ShinyApps.io free tier deployment will limit model execution to a single CPU.
Our tutorial has a number of limitations. One issue we do not consider are projects where data, used to derive parameters or the parameters themselves used by the simulation model, may need to be kept private due to governance or ethical reasons. In these instances hosting a model interface on a service such as streamlit community cloud is more challenging. This is a contemporary problem for the UK NHS. Initiatives such as OpenSafely have emerged to tackle reproducible pipelines and could support deriving model parameters43. There is likely much that can be learnt from the Health Economic Evaluation community and research in R where models access secure data and parameters remotely using a secure API44.
While we have discussed creating model interfaces and wrapper functions for Python DES models, we have not been prescriptive about how these models are logically structured internally or what else should be included. Others have argued that standardisation of code and its organisation will benefit transparency and reuse in Health Economic Evaluation45,46. This includes naming conventions, unit testing, and project documentation. The inclusion of comprehensive documentation has been identified as a primary motivator of reuse of code47.
Our tutorial focused on the mechanics of building a usable streamlit interface for DES models, but we have not described detailed customisation options for interfaces. These might, for instance, be important for models where NHS or research funder branding are needed. Basic options provided by streamlit include the ability to display NHS or funder logos using the st.image() function. More flexible and detailed control of appearance can be accessed via streamlit’s theming options, e.g., controlling font, and background colour of different sections or pages.
When compared to commercial DES software packages that are commonly used in health research, such as Simul8, or AnyLogic, a limitation of our approach is that we do not display a dynamic patient pathway or queuing network that updates as the model runs a single replication. This is termed Visual Interactive Simulation (VIS) and can help users understand where process problems and delays occur in a patient pathway48; albeit with the caveat that single replications can be outliers. A potential FOSS solution compatible with a browser-based app could use a Python package that can represent a queuing network, such as NetworkX49, and displaying results via matplotlib. If sophisticated VIS is essential for a FOSS model then researchers may need to look outside of web apps; for example, salabim provides a powerful FOSS solution for custom animation of DES models.
One aim of Open Science is to increase the accessibility of research. The code for healthcare DES models, often tackling important treatment pathways, can be shared alongside publications, but requires specialist skills to use and run. Building on work from other health data science disciplines, we propose that web apps offer a user-friendly interface for healthcare DES models that increases research accessibility to the NHS and researchers from other disciplines. We provide an approach to structuring DES model code in Python and a worked example linking this to a streamlit interface. Further work could consider interface design, and visual interactive simulation.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with NIHR Open Research
Already registered? Sign in
If you are a previous or current NIHR award holder, sign up for information about developments, publishing and publications from NIHR Open Research.
We'll keep you updated on any major new updates to NIHR Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)